Cohort Retention
Cohort Retention is an important measurement that reflects a business's health. Retention metric is often analyzed across groups of customers that share some common properties, hence the name Cohort Retention Analysis.
Cohort Retention Analysis is a powerful technique that every business owner should know. For more details, please check our dedicated guide on Build Cohort Retention Chart using Holistics.
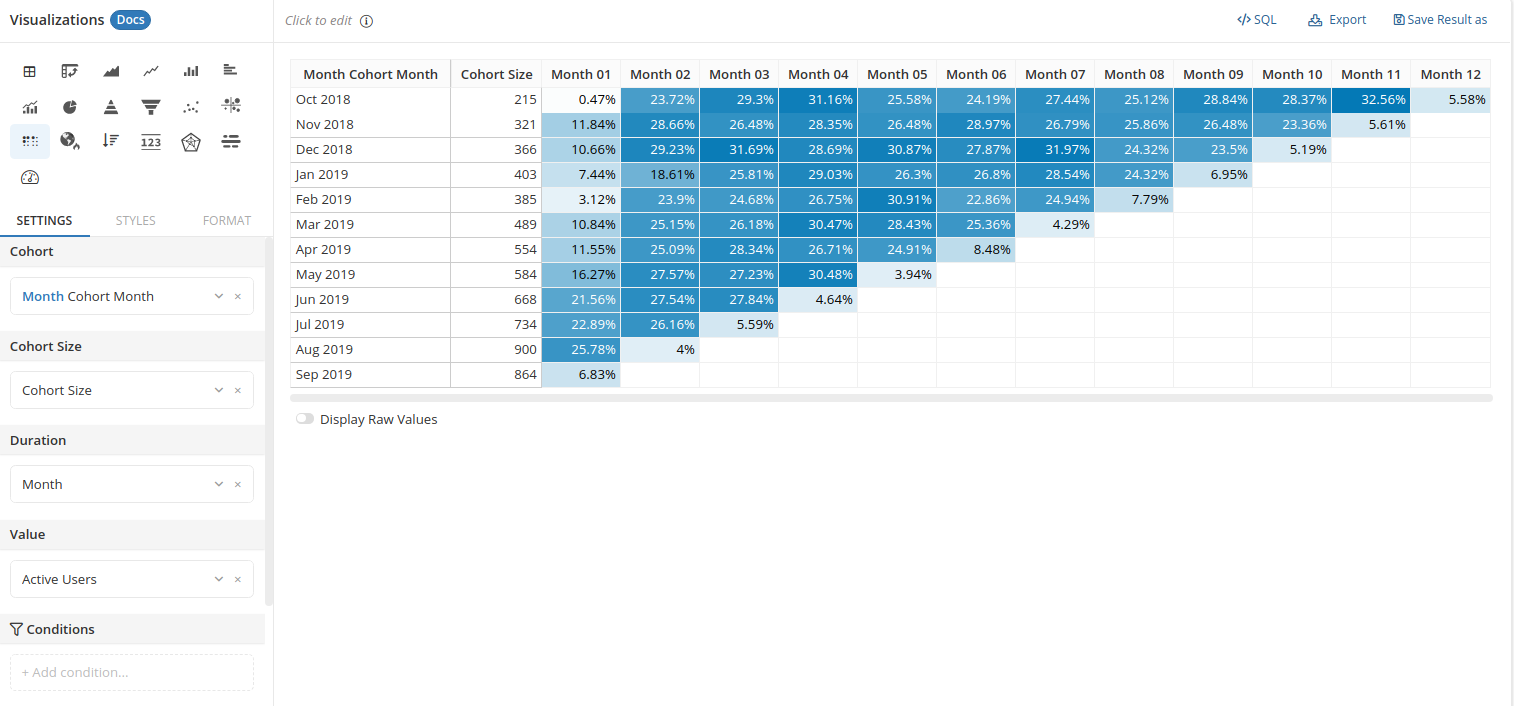
There are many ways to visualize cohort retention, but the most common and useful way is using a two-dimensional "heat map" whose cells are colored based on their values. This is where Holistics's Retention Heatmap comes in.
When to use Retention Heatmap
Displaying cohort retention can be done with Table visualization and conditional formatting, but it is much easier with a dedicated visualization that is Retention Heat Map.
Create a Retention Heatmap
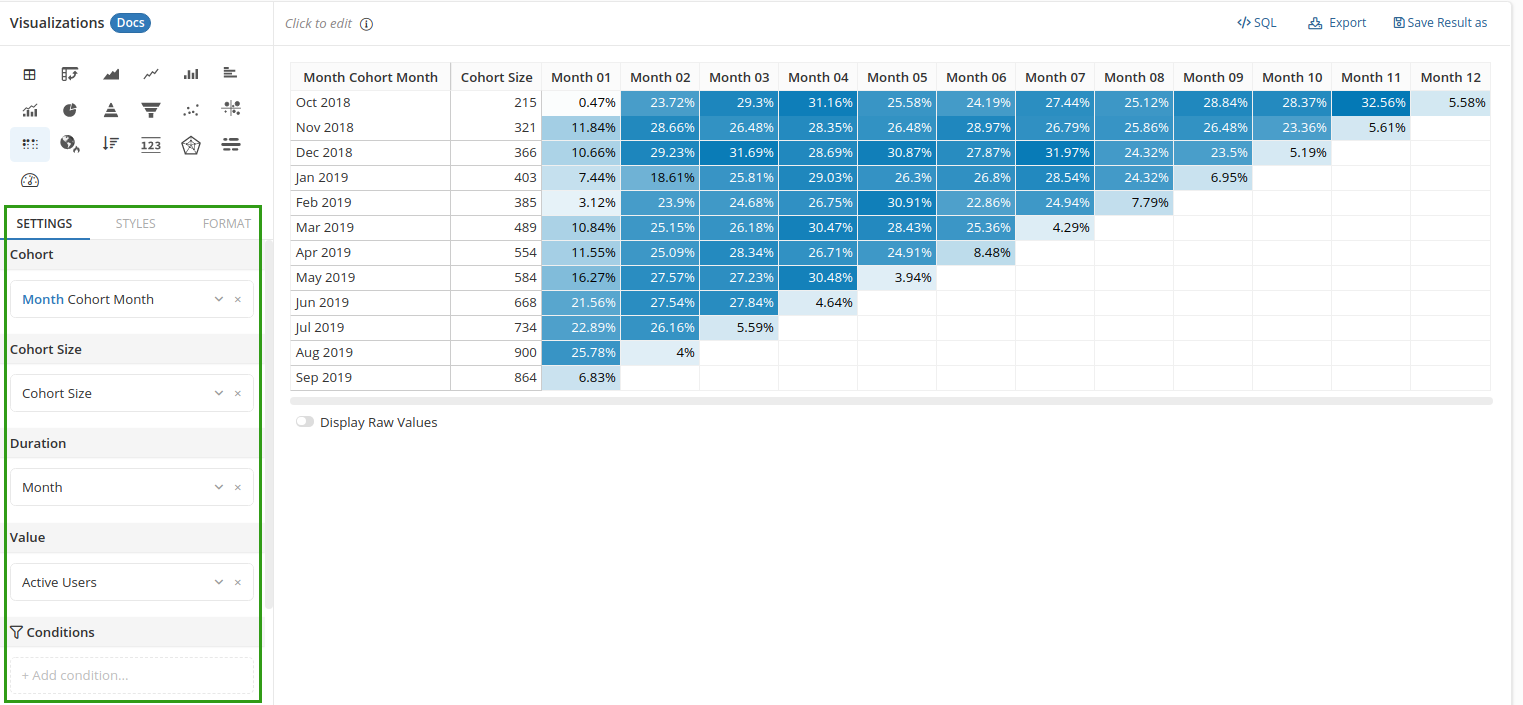
To create a Retention Heatmap, you need to fill up the following fields:
- Cohort: the dimension that defines your cohort. For example: users' registration month, user's age group... This dimension is placed vertically.
- Cohort Size: the variable contains number of users in the cohort
- Duration: the second dimension used to organize the data points. Typically this is "the Nth month after registration".
- Value: the raw count of your "returned customers". This will be divided by Cohort Size to get the retention rate.
Note: When the cohort size is not selected, the first month would become the cohort size
Ordering your columns
The variable you use for Duration will always be converted into string type, and your columns will be in alphabetical order.
For example, your Duration variable is "Month name" whose values are:
'Jan 2019', 'Feb 2019', 'Mar 2019', 'Apr 2019'...
The columns will appear in the alphabetical order, which is not exactly what you want:
'Apr 2019', 'Feb 2019', 'Jan 2019', 'Mar 2019'...
To have your columns in your desired order, instead of using the month names, you can use month's numerical representation:
'2019-01', '2019-02', '2019-03', '2019-04'...
In case your Duration column is of numeric type, you will need to create a custom dimension to prepend zeroes to your variable. In other words, you will need to turn your variable from this:
1, 2, 3, 4, ..., 10, 11, ...
To this:
'01', '02', '03', '04', ..., '10', '11', ...