Model Storage Settings
A grasp of these concepts will help you understand this documentation better:
Introduction
Because Holistics will write data to your data warehouse with this setting, ensure that your DB credentials has write access before enabling this mode.
In both Holistics's Import Models and Query Models, Holistics writes data to your data warehouse to either make it available for querying, or to improve query performance. There are four writing modes supported in Holistics:
- Full mode: The destination table will be replaced completely by a new result set.
- Append mode: A full snapshot of the source data will be appeneded to the destination table, and old record are left intact. This mode is available for Import Models only.
- Incremental mode: New records will be appended to the destination table.
- Upsert mode: A combination of UPDATE and INSERT. Records with changes will be updated, and new records will be inserted into the destination table.
These modes behave a bit differently between Import Models and Transforms Models, and we will go into the details below.
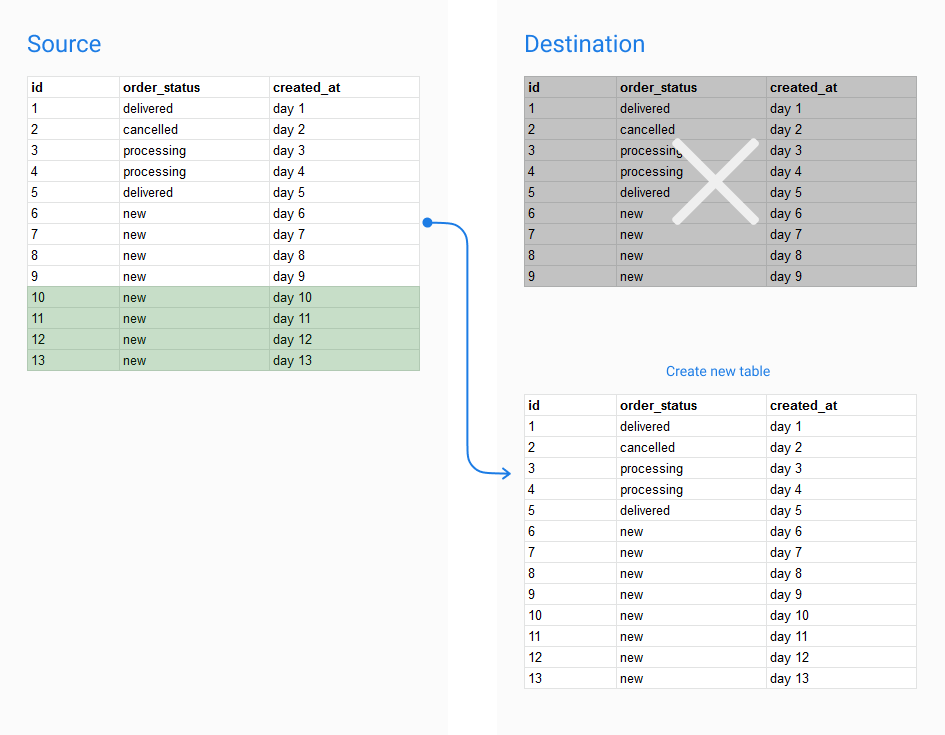
Full mode
You may want to use Full mode if your data is small, the records change regularly, and you do not need to retain the history of your data.
Note: If you are importing a large table (like events or log tables), you should avoid Full mode and use Incremental mode instead.
Mechanism:
This mode works similarly in both Import and Query Models. Basically, Holistics will drop the old table in your destination if (if it already exists), and replace it with new data.
- In Import Models, this means the destination table will be replaced by the most recent snapshot of your source data.
- In Query Model, the destination table will be replaced by the new result set produced by the model's SQL.
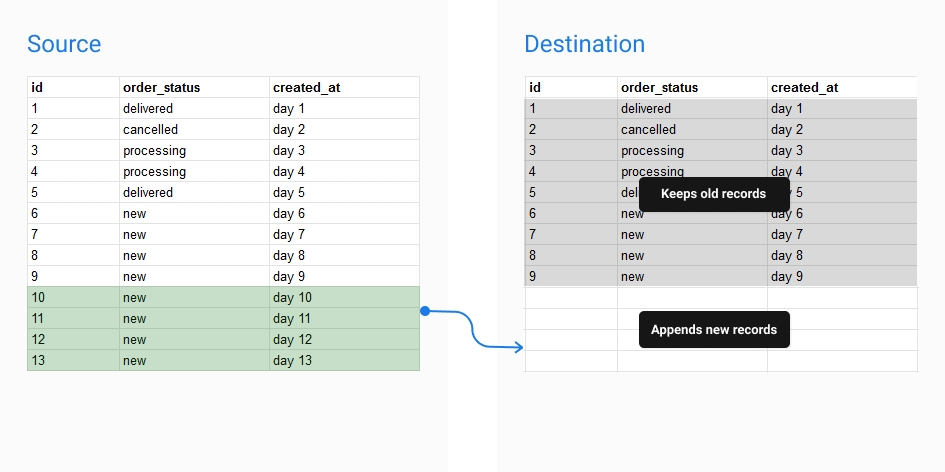
Append mode
You may want to use Append mode if your source records are updated directly, and you want to retain a log of those changes. In this mode, a full copy of your source table will be appended to the destination table.
Note: The Append mode is only availabe for Import Models.
Mechanism:
Holistics will get all records from the source, and insert them to the existing destination table. Old records are left untouched.
- Pros: Can retain historical changes of your data.
- Cons: Your destination table will become bloated quickly if the run frequency is high.

Incremental mode
This mode behaves differently between Import and Query Models: it can reduce the amount of data scanned in Import Models, but cannot do so in Query Models.
In Import Models
This should be used if your source table is large, and past records do not change. In this mode, only new records from the model's query will be appended to the destination table.
Note: This mode is only available for SQL data sources.
Mechanism:
To use Incremental mode, you only need to specify an increment column, and Holistics will use that column to determine the data range to be queried from the source. Depending on your case, this can be a created_at or an updated_at column.
How the import will work:
-
Step 1: get the current max value of the increment column from the destination table (let's call it
max_value_of_destination)SELECT MAX(incremental_column) FROM dest_table -
Step 2: Only retrieve records whose value of the increment column is greater than the current max value above:
SELECT source_dataFROM source_tableWHERE incremental_col > max_value_of_destination -
Step 3: Insert all new records retrieved in Step 2 to the destination table.
This way, the import run time is reduced significantly because Holistics only needs to scan a section of your data, not the whole source table.
In Query Models
At the moment, Holistics Query Model cannot dynamically limit the range of data it will query. The Incremental Mode can only determine which records to be inserted into the destination table.
How it works:
-
Step 1: get the max value of the increment column from the destination table (let's call it
max_value_of_destination):SELECT MAX(incremental_column) FROM dest_table -
Step 2: Run the model's SQL as-is to produce a result set. For example, we have an
orders_aggregationmodel that counts the number of orders created daily:SELECTcreated_date, count(*) as orders_countFROM ordersgroup by 1 -
Step 3: Holistics uses
max_value_of_destinationto filter the result set produced in Step 2, and insert the filtered records into the destination table.Basically, the process will look something like:
INSERT INTO dest_schema.orders_aggregationWITH base as (SELECTcreated_date, count(*) as orders_countFROM ordersgroup by 1)SELECT * FROM baseWHERE created_date > {{max_value_of_destination}} -- Filter is outside of the CTE
This means the whole source table is still scanned, and the process can be potentially costly.
Upsert mode
This mode also behaves differently between Import and Query Models.
In Import Models
In case your source table is large and past records are updated, this should be used.
- If there are new records, those will be appended to the destination table.
- If the existing records from the source table are updated, we will update the corresponding records in the destination table.
Note: This mode is only available for SQL data sources.

Mechanism:
To use this mode, you will need to specify both the Primary Key and the increment column. Normally they are the the id and updated_at columns.
-
Step 1: Get the max value of hte increment column from the destination table (let's call it
max_value_of_destination')SELECT MAX(incremental_col) FROM des_table -
Step 2: Retrieve the source records with increment column's value greater than
max_value_of_destinationSELECT primary_key, source_dataFROM source_tableWHERE incremental_col_source > max_value_of_destination -
Step 3: Delete records in the destination table with
primary_keyexisting in the result set of Step 2. -
Step 4: Insert all new records produced in Step 2 to the destination table.
Similar to Incremental mode, this can also reduce your data import run time.
In Query Models
Upsert mode in Query Models shares the limitation with the Incremental mode: the WHERE filter is not applied within the initial query, but applied to the result set produced by the query.
Therefore, Upsert mode in Query Models is still potentially costly.
FAQs
I migrated the destination tables in my data warehouse. The persisted models that use these tables encounter errors when I use them in my queries.
You will need to reset the storage settings of persisted models if you have made changes to the schema of the destination table in your data warehouse.
For example, your Query/Import Models' destination tables reside in schema A of your data warehouse. You then relocate these tables from schema A to schema B in your data warehouse. When this happens, Holistics will not able to to detect the new schema of the destination tables. Subsequently, all queries that use these persisted models will fail as they would use the old schema.
To resolve this issue, you will need to change the schema of your persisted models:
-
To reset the schema of Query Models, you will need to reset the storage settings and create a new Storage Setting with the new schema.
-
To reset the schema of Import Models, go to Advanced Settings > Destination Settings and edit your schema.
What if I still want to do incremental transform?
As stated in Query Models docs, we do not intend to make this feature a full-fledged ETL solution. Normally for more advanced data transformation use cases, we recommend our customers to checkout dedicated transformation tools like dbt or Dataform.