Better than YAML
Introduction
“Aren’t all YAML-based analytics modeling languages similar? Why did Holistics have to invent a new modeling language instead of just use YAML?”
Most “Analytics as Code” solutions on the market use YAML as their underlying modeling markup syntax. While this is a popular choice among BI vendors, YAML remains a general-purpose markup language that poses many limitations when it comes to analytics development.
This document explains the limitations of YAML-based modeling language, and how AMQL addresses those limitations.
YAML is ambiguous and error-prone
YAML is designed for human readability, and it tries to be “helpful” by automatically interpreting values. But this "helpfulness" creates a minefield of edge cases and inconsistencies.
Inconsistent type parsing
Consider this seemingly innocent example:
versions:
- test # Return 'test' (string)
- 10.5.1 # Return 10.5 (number)
- 1e+5 # Return 10000 (scientific notation)
config:
enabled: yes # String or boolean? Depends on your parser!
release: 2023-05-01 # String or date?
What actually gets parsed for versions? ["test", 10.5, 100000] . The version number becomes a floating-point number, and the product code is interpreted as scientific notation — completely corrupting your intended data structure (all should be strings).
Also, the same YAML document parses differently depending on which parser and version you use. Try parsing this identical YAML in Python vs Node.js. Python returns True (boolean) for the field enabled, whereas NodeJS returns 'yes' (string).
Whitespace indentation nightmares
Furthermore, YAML uses “whitespace indentation” to define nested structures. This makes it really easy to cause error. Imagine working on a big YAML file and accidentally make a small spacing mistake in the code:
dimensions:
- name: id
label: "ID"
- name: email
label: "Email"
Can you spot where the error happens? Not very easy to do, especially with large files.
These ambiguities turn simple mistakes into major debugging headaches, especially in large configuration files.
AMQL provides clear, analytics-first syntax
AMQL eliminates these ambiguities by design with a clean, explicit syntax:
// users.model.aml
Model users {
type: 'table'
label: 'Users'
data_source_name: 'snowflakedb'
table_name: 'public.users'
dimension id {
label: 'ID'
type: 'number'
definition: @sql {{#SOURCE.id}};;
}
dimension email {
label: 'Email'
type: 'text'
definition: @sql {{#SOURCE.email}};;
}
measure user_count {
type: 'number'
label: 'Count Users'
definition: @sql count({{#SOURCE.id}});;
}
}
Notice the difference: analytics objects are first-class citizens in AMQL. Models, dimensions, and measures are native language constructs with explicit types, not generic data structures left to interpretation.
Furthermore, the curly bracket { syntax eliminates indentation ambiguity while creating a programming-friendly language that reads naturally and maps directly to analytics concepts.
YAML is schemaless with no type system
Perhaps the most fundamental limitation of YAML for analytics development is its complete lack of a type system and schema validation. This severely impacts both your analysts' productivity and your analytics projects' reliability, creating cascading problems that grow with your codebase.
No enforcement of required fields
YAML's schemaless nature means there's no built-in way to define what fields are required, what types they should be, or what relationships exist between different parts of your model:
# sales_dashboard.yaml
dashboard:
title: Sales Performance
charts:
- name: Revenue by Quarter
metric: quarterly_revenue
chart_type: bar
- name: Conversion Rate
metric: conversion_rate
**# Oops! chart_type is missing, but YAML doesn't care**
Without schema validation, YAML silently accepts missing required properties. These issues only surface at runtime—typically after production deployment—and often manifest as silent corruptions where charts display convincing but entirely wrong data.
No autocomplete and inline documentations
Furthermore, YAML's schemaless nature creates a development experience that lacks two critical productivity features: autocomplete and inline documentation.
Without code suggestions or inline docs, analysts must memorize property names, valid values, and structure details—or constantly refer to external documentation.
metrics:
- name: revenue_growth
time_grain: quater # Typo for "quarter" goes undetected
# What are valid compare_methods? No way to know without external docs
compare_method: precentage_change # Another typo that YAML happily accepts
This lack of guidance leads to countless wasted hours on trial-and-error, debugging typos, and hunting through documentation.
AMQL has robust type system
AML, on the other hand, is a strongly-typed language (think TypeScript but for analytics) with a powerful built-in static type system. This allows enhancing the developer experience with instant error feedback, smart auto-completion and template suggestions directly within the IDE.
- Smart autocomplete: Get instant suggestions for valid attribute values
- Inline documentation that explains the parameters without leaving your editor.
- Intelligent refactoring: Go to definition, find all references, and track dependencies between dashboards, reports, and metrics
- Instant error feedback catches mistakes as you type them
- Compile-time validation that catches errors before deployment
Here are a few examples:
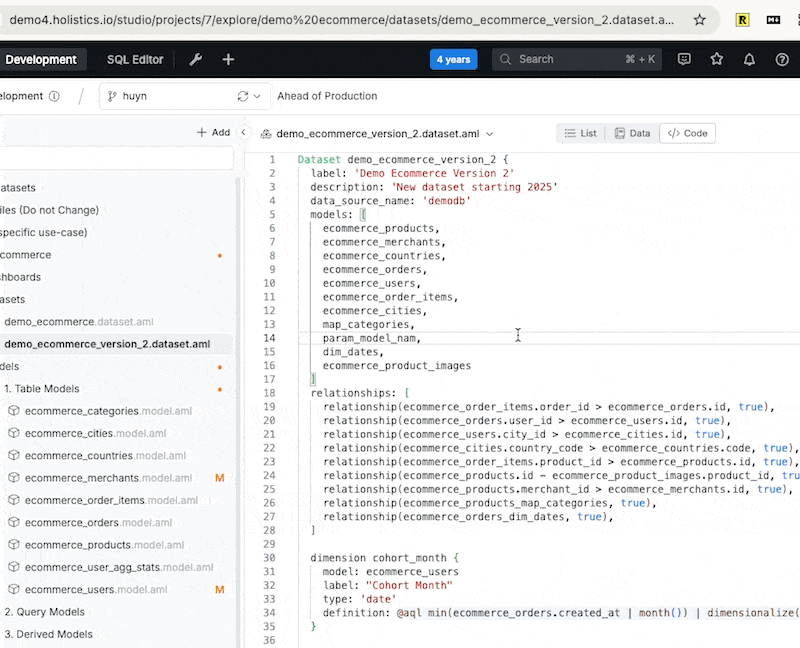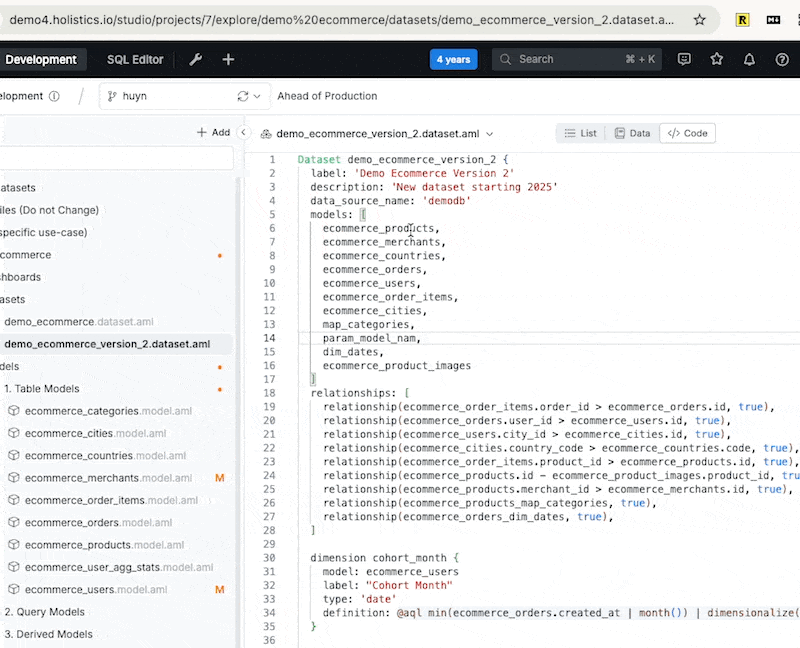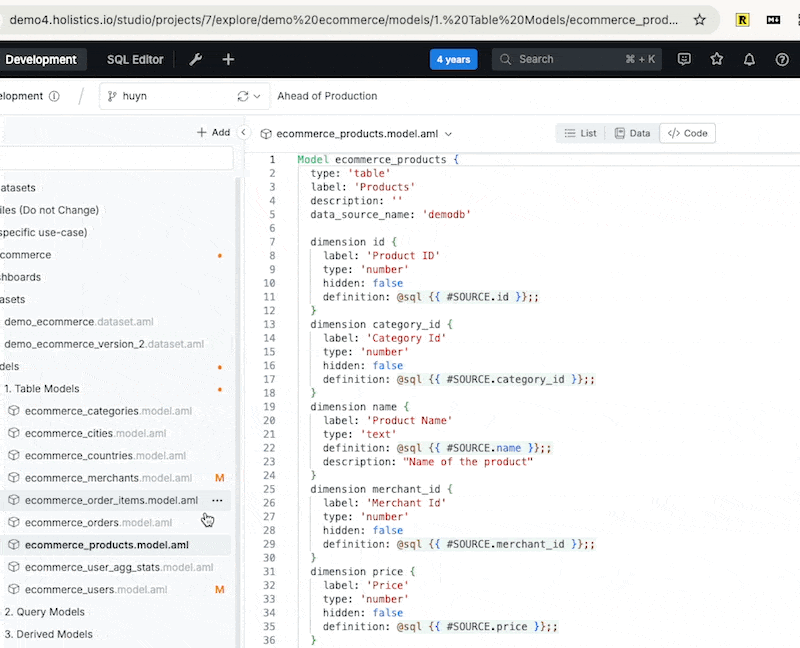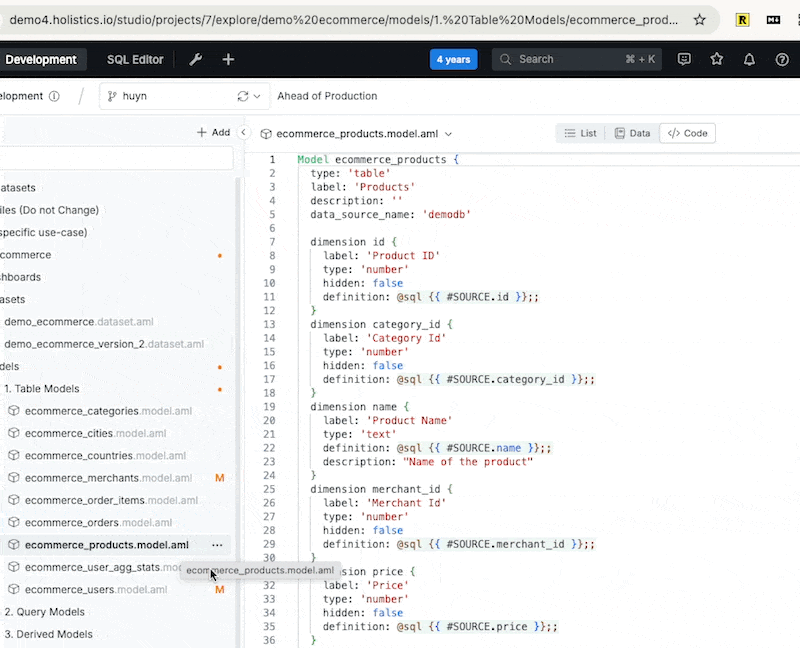
Autocompletion within the analytics IDE: the IDE auto-suggests suitable values for the “type” property of a dimension.
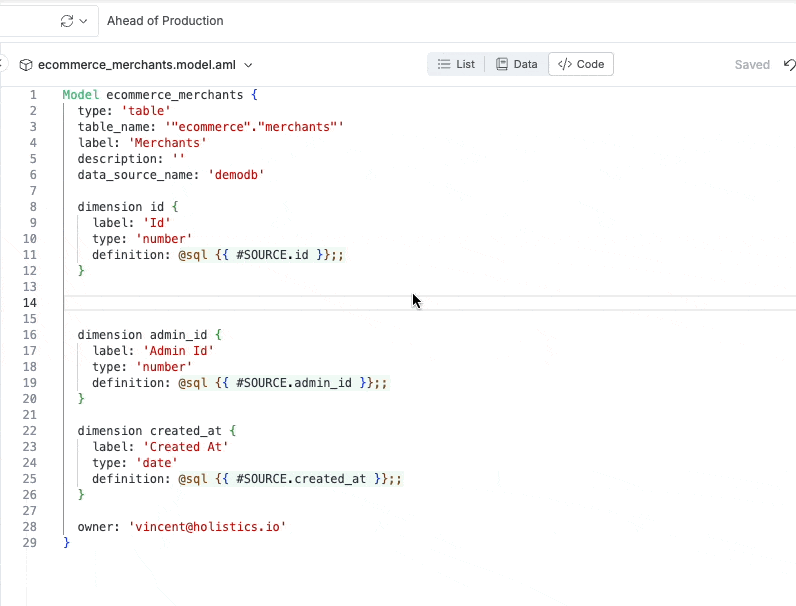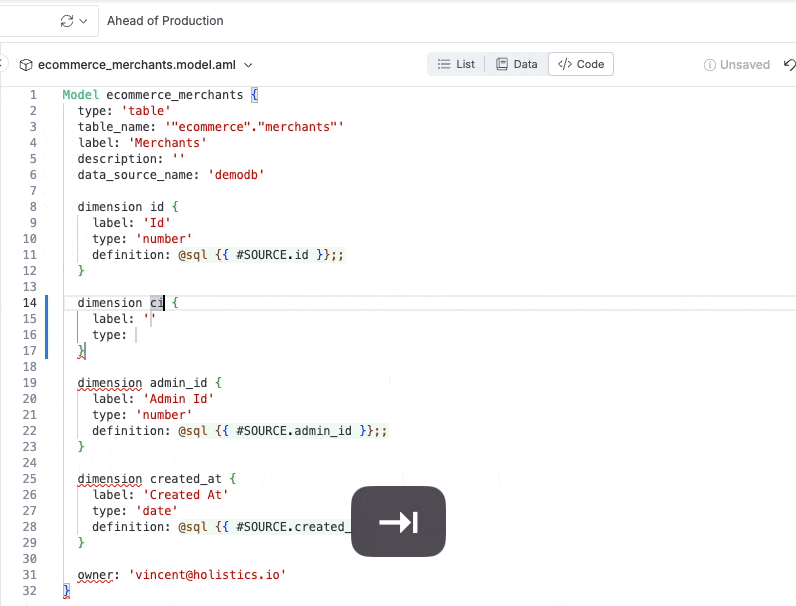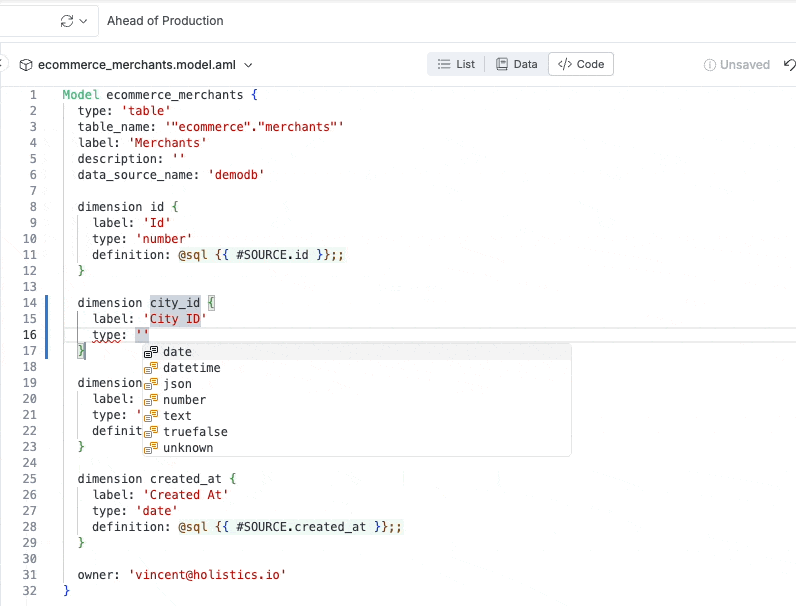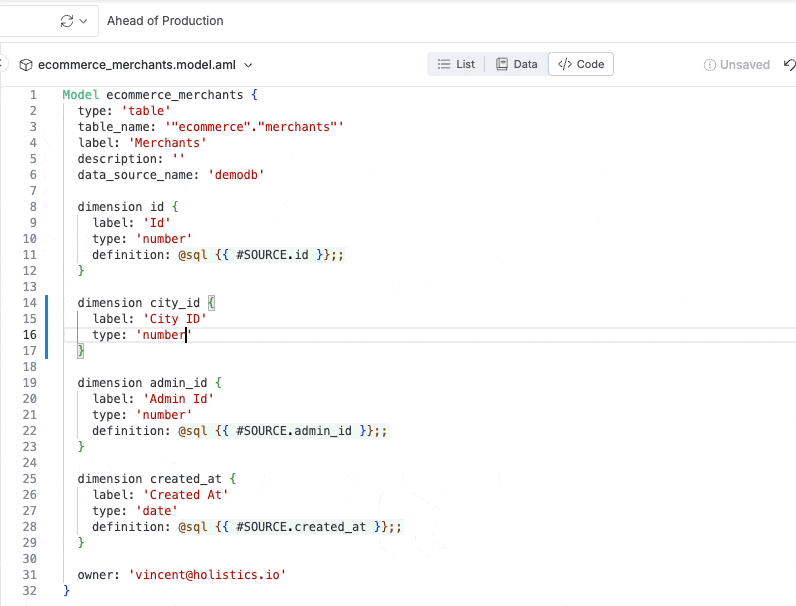
Inline docs shown when hovering over code object
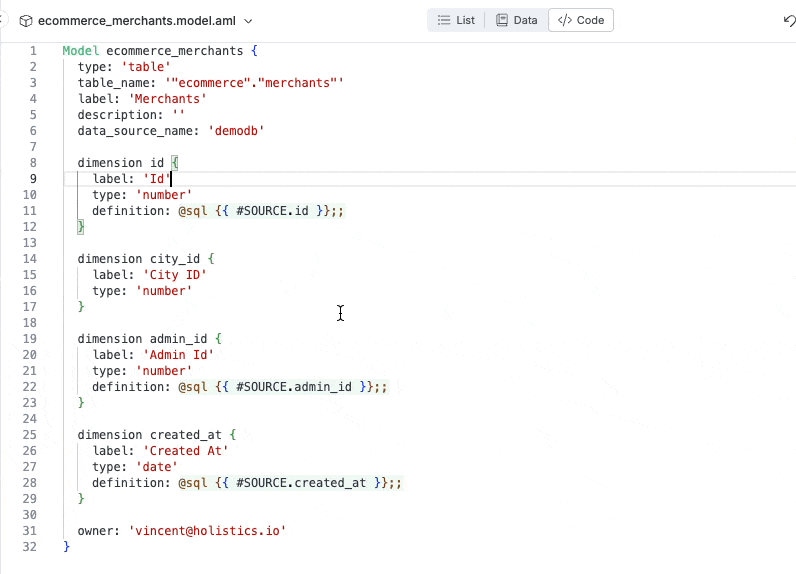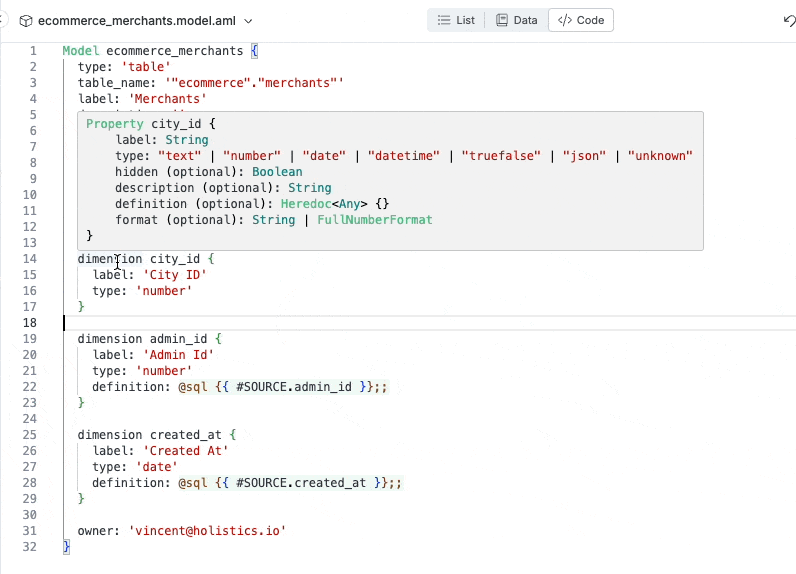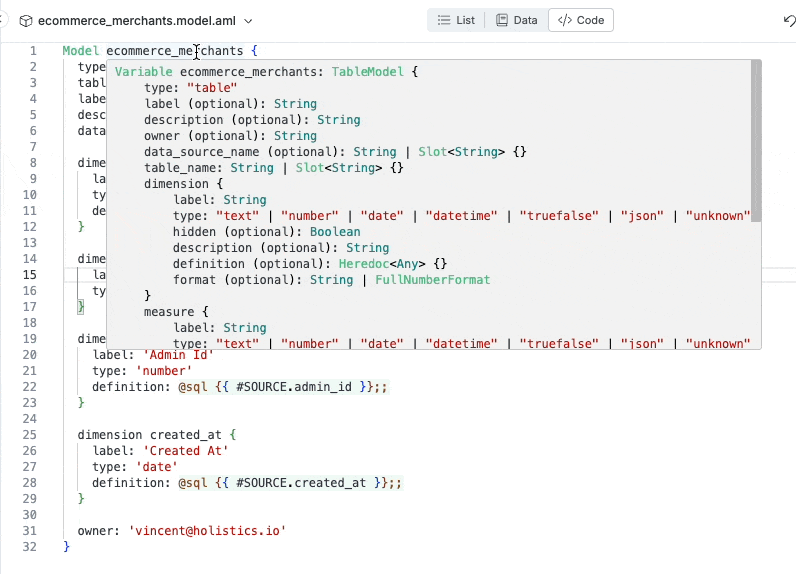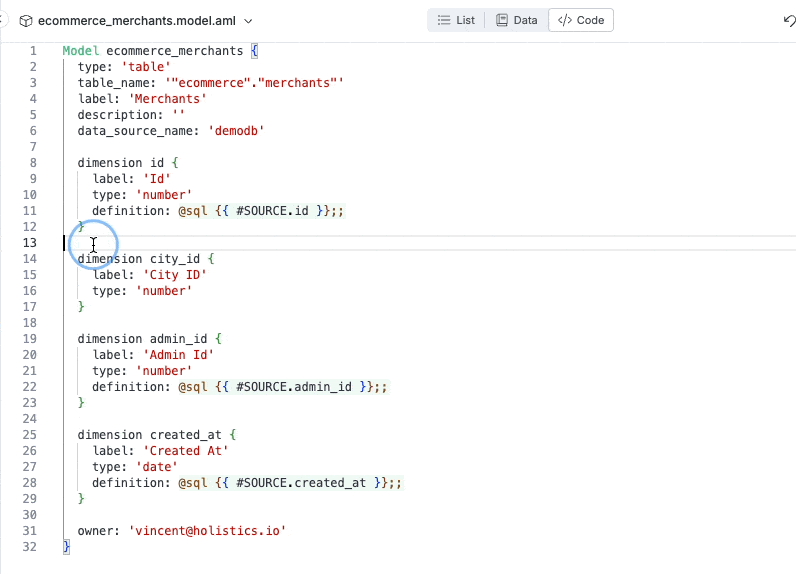
Instantly raise errors when there’s error (duplicate dimension).
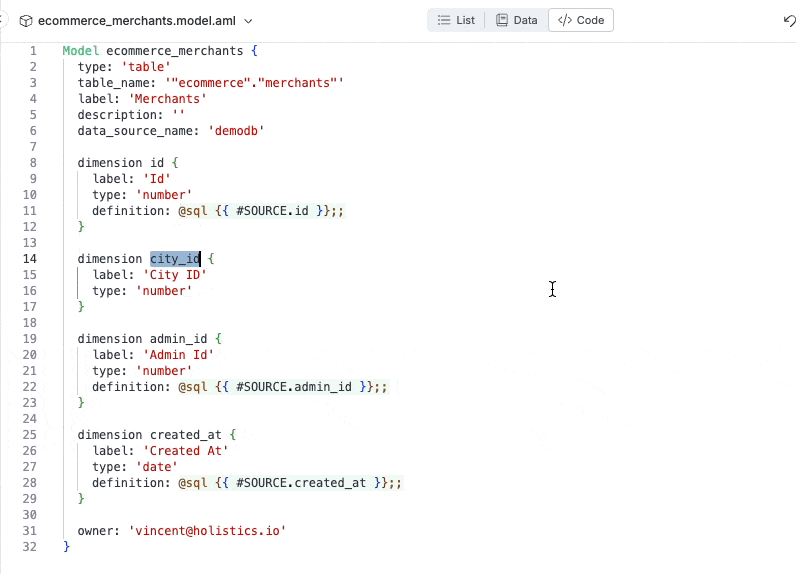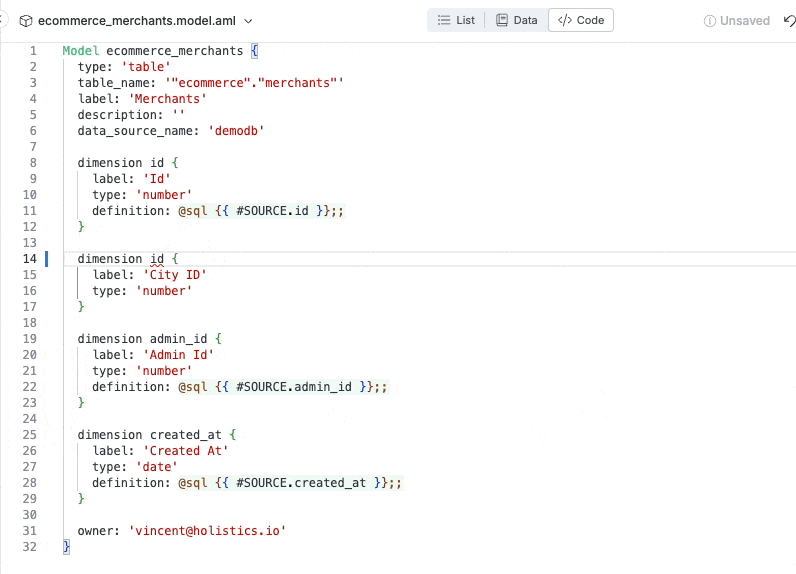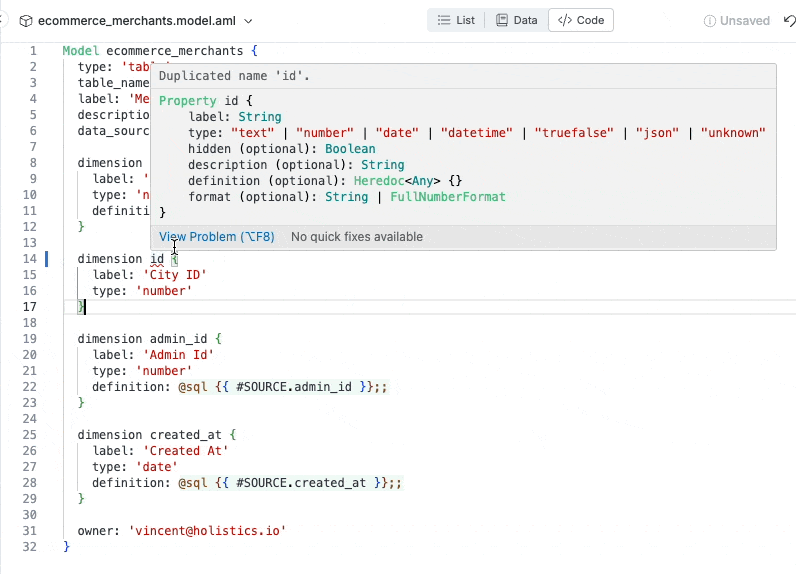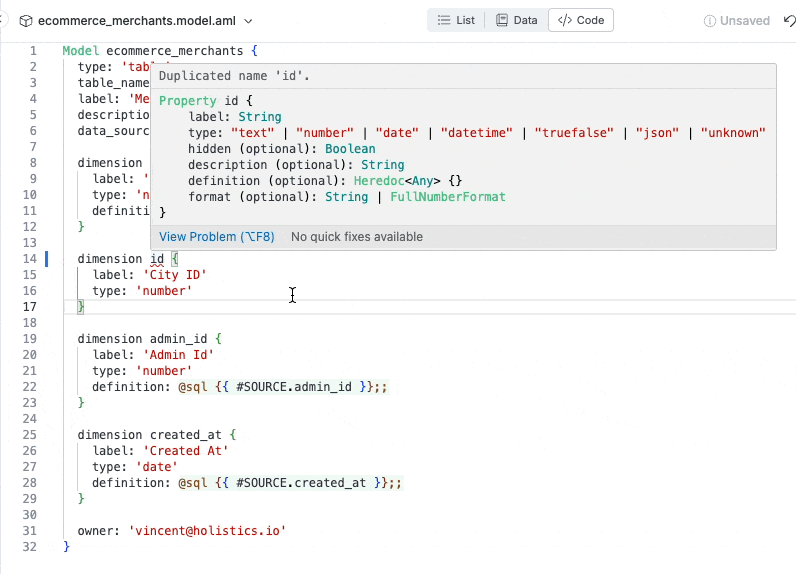
Raising error instantly when required attributes not declared
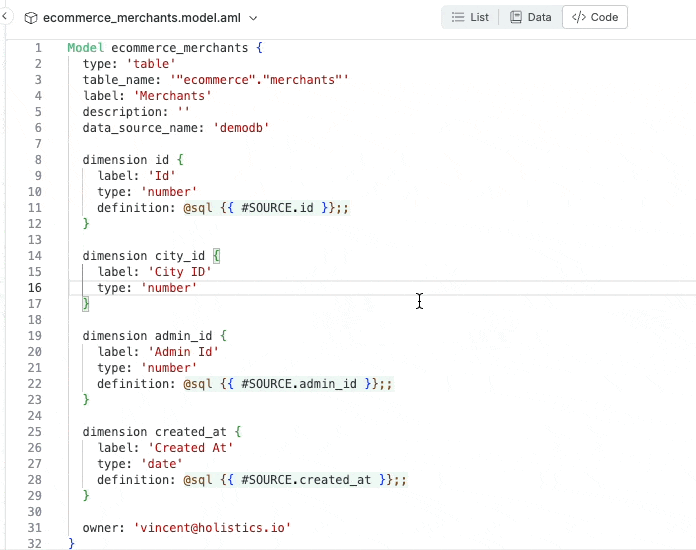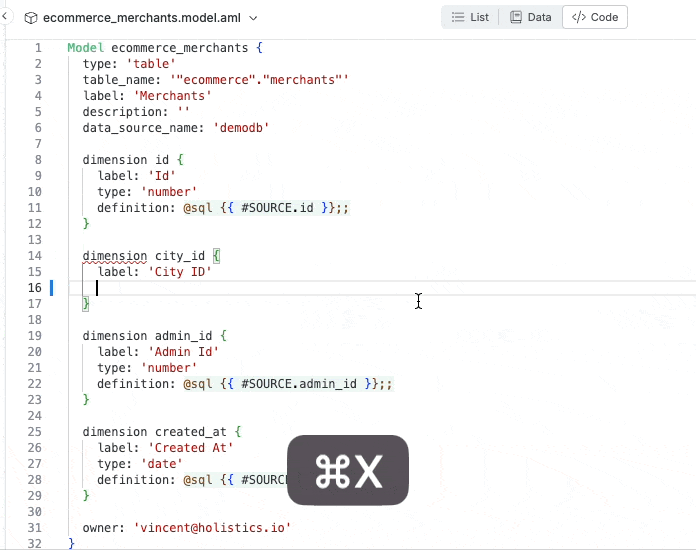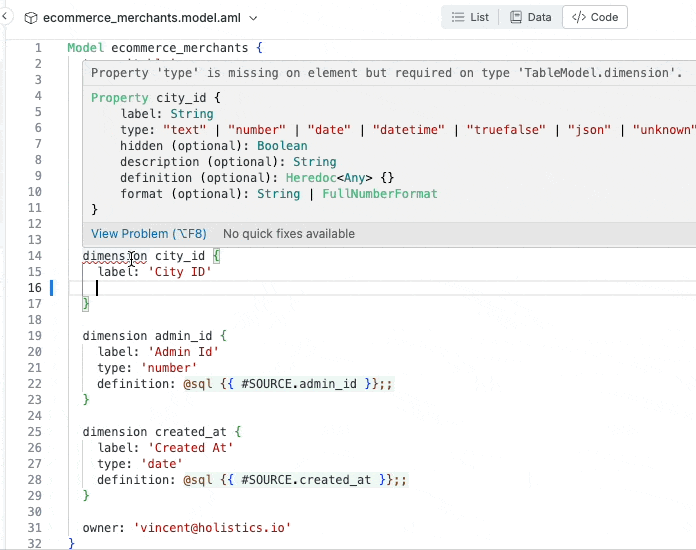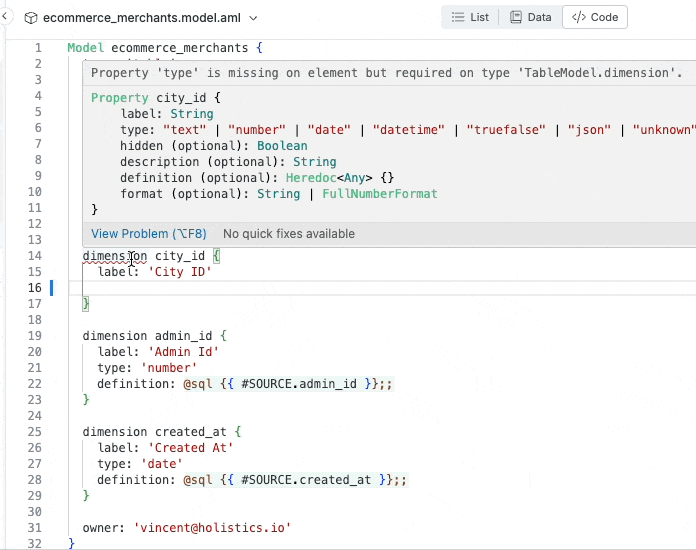
Jumps to the model’s definition code by control-clicking on name.
YAML lacks programmability and reusability
YAML's nature as a pure data serialization format means it completely lacks programmability features. This forces analytics teams into inefficient workflows and prevents the kind of code reuse that's standard in modern development.
No variables, no functions, no abstractions
Want to define a constant once and reuse it? Want to parameterize your logic? Want to create reusable analytics components? YAML offers no native way to do any of this:
- No variables to store and reuse values
- No functions to encapsulate and parameterize logic
- No template mechanism for reusing structure
- No inheritance or extension mechanisms
- No conditional logic or control flow
The result is analytics code that constantly violates the DRY (Don't Repeat Yourself) principle.
Without programming constructs, YAML forces you to duplicate code for similar analytics components:
metrics:
# Define a metric for daily active users
- name: daily_active_users
type: count_distinct
sql: "SELECT COUNT(DISTINCT user_id) FROM events WHERE event_date = CURRENT_DATE"
# Want weekly active users? Copy-paste and modify
- name: weekly_active_users
type: count_distinct
sql: "SELECT COUNT(DISTINCT user_id) FROM events WHERE event_date >= CURRENT_DATE - 7"
# Monthly active users? Copy-paste again
- name: monthly_active_users
description: "Users active in the last 30 days"
type: count_distinct
sql: "SELECT COUNT(DISTINCT user_id) FROM events WHERE event_date >= CURRENT_DATE - 30"
This approach is not only tedious but dangerously error-prone. When business logic changes (like how you define an "active" user), you must find and update every copy of the logic. Also, you can’t build derived metrics like “daily active users in Europe” that reference and extend existing metric — instead, you’re forced to recreate the entire calculation from scratch.
The templating trap: YAML + Jinja
Backed into a corner by YAML's limitations, many platforms resort to bolting on external templating engines. DevOps tools like Ansible have grafted string-based templating systems like Jinja onto YAML. dbt, a popular data transformation tool, also added Jinja templating on top of their SQL-based transformation language.
This is how adding Jinja templating to a YAML-based modeling language looks like:
# Data modeling with Jinja templating - a notorious pain point
metrics:
{% for period in ['daily', 'weekly', 'monthly'] %}
{% set days = 1 if period == 'daily' else 7 if period == 'weekly' else 30 %}
- name: {{ period }}_active_users
description: "Users active in the last {{ days }} days"
type: count_distinct
sql: "SELECT COUNT(DISTINCT user_id) FROM events WHERE event_date >= CURRENT_DATE - {{ days }}"
{% endfor %}
While this approach might seem clever at first glance, it creates a fundamentally flawed hybrid that combines the worst aspects of both technologies:
- Multi-layer parsing nightmares: The code must pass through multiple parsing layers (Jinja then YAML), creating cryptic errors that reference generated code rather than your source
- Runtime-only error detection: Unlike proper programming languages, errors with undefined variables, type mismatches, and logic bugs only surface when templates execute, leaving you blind during development.
This approach isn't programming-it's string manipulation masquerading as logic. Instead of coherent language constructs, you get a fragile chain of text processing that breaks in mysterious ways.
The fact that teams resort to this approach highlights how desperately they need actual programming constructs that YAML simply cannot provide.
AMQL is fully programmable and reusable
AMQL takes a fundamentally different approach by being a true programming language designed specifically for analytics. This means you can express both structure and computation in a single, coherent language with proper abstractions, control flow, and composition—eliminating the need for these dangerous workarounds.
AMQL supports features like:
- Declare parameterized logic (functions)
- Define reusable variables (constants)
- Build analytics objects on top of one another (extend)
- Define new metrics by composing existing metrics (metrics composition)
The code sample below in AMQL defines models and datasets for calculating user conversion rates across multiple time granularities. Thanks to AMQL’s reusability, we are able to deconstruct the logic into modular components, and compose them on the spot into multiple different metrics.

Conclusion
We’re not the first to recognize YAML's limitations for analytics. Even Looker, one of the pioneers of analytics-as-code, eventually abandoned their YAML-based LookML 1.0 in favor of creating their own proprietary language (LookML 2.0). As Looker's engineering team explained when announcing the change: "YAML has a lot of sharp edges... Building a parser with YAML wasn't sustainable... YAML is not a standard designed nor intended for data modeling."
However, while Looker solved YAML's ambiguity and tooling issues, LookML 2.0 remains essentially a markup language—it lacks true programmability features like variables, functions, and composition. AMQL goes further by being a fully programmable language that enables the code reuse and composition that analytics teams desperately need.
We designed AMQL to systematically address every limitation of YAML for analytics development. Where YAML fails due to its nature as a general-purpose data format, AMQL succeeds by being purpose-built for analytics from the ground up through three foundational principles:
- Clear, unambiguous syntax with first-class analytics concepts that eliminate YAML's interpretation ambiguities
- Robust static type system that enables intelligent IDE features like autocomplete, inline documentation, and instant error detection
- Native programmability to enable true code reuse and composition without dangerous workarounds
Your analysts deserve something better than YAML.
tldr: AMQL vs YAML
| Category | YAML | AMQL |
|---|---|---|
| Type Safety | ❌ Schemaless, no type checking ❌ Silent errors at runtime ❌ Ambiguous value interpretation | ✅ Strong static type system ✅ Compile-time error detection ✅ Explicit, unambiguous syntax |
| Developer Experience | ❌ No autocomplete or inline docs ❌ Manual trial-and-error workflow ❌ Whitespace indentation errors | ✅ Smart autocomplete & suggestions ✅ Inline documentation ✅ Instant error feedback |
| Reusability | ❌ No variables, functions, or abstractions ❌ Forces code duplication ❌ Dangerous templating workarounds | ✅ Variables, functions, and composition ✅ True code reuse and modularity ✅ Native programmability |
| Analytics Focus | ❌ General-purpose data format ❌ No understanding of analytics concepts | ✅ Purpose-built for analytics ✅ First-class analytics objects |
| Parsing Consistency | ❌ Different results across parsers ❌ Version-dependent behavior ❌ "Helpful" but unpredictable interpretation | ✅ Consistent, predictable parsing ✅ Analytics-specific language constructs |
Bottom Line: YAML is a data serialization format trying to be an analytics language. AMQL is a true programming language designed specifically for analytics development.