Pre-aggregate Persistence
Aggregate Awareness requires a physical table in your data warehouse. You have two options for providing this table:
- Built-in persistence: Holistics creates and manages the table for you
- External persistence: You point Holistics to an existing table (from dbt, Airflow, etc.)
Built-in persistence
With built-in persistence, Holistics creates and refreshes pre-aggregated tables directly in your data warehouse. Use this when you don't have existing tables and want Holistics to handle everything.
Persistence types
Choose between full and incremental persistence based on your data volume and refresh needs.
FullPersistence
Rebuilds the entire table from scratch each time. Best for smaller datasets or when you need a clean slate on each refresh.
persistence: FullPersistence {
schema: 'persisted'
}
IncrementalPersistence
Appends new records and updates existing ones. Identifies new records using incremental_column and updates based on primary_key. Best for large, append-heavy datasets like time-series data.
persistence: IncrementalPersistence {
schema: 'persisted'
incremental_column: 'created_at_day'
primary_key: 'created_at_day'
}
Always specify primary_key (typically the same as incremental_column) to ensure records are upserted correctly.
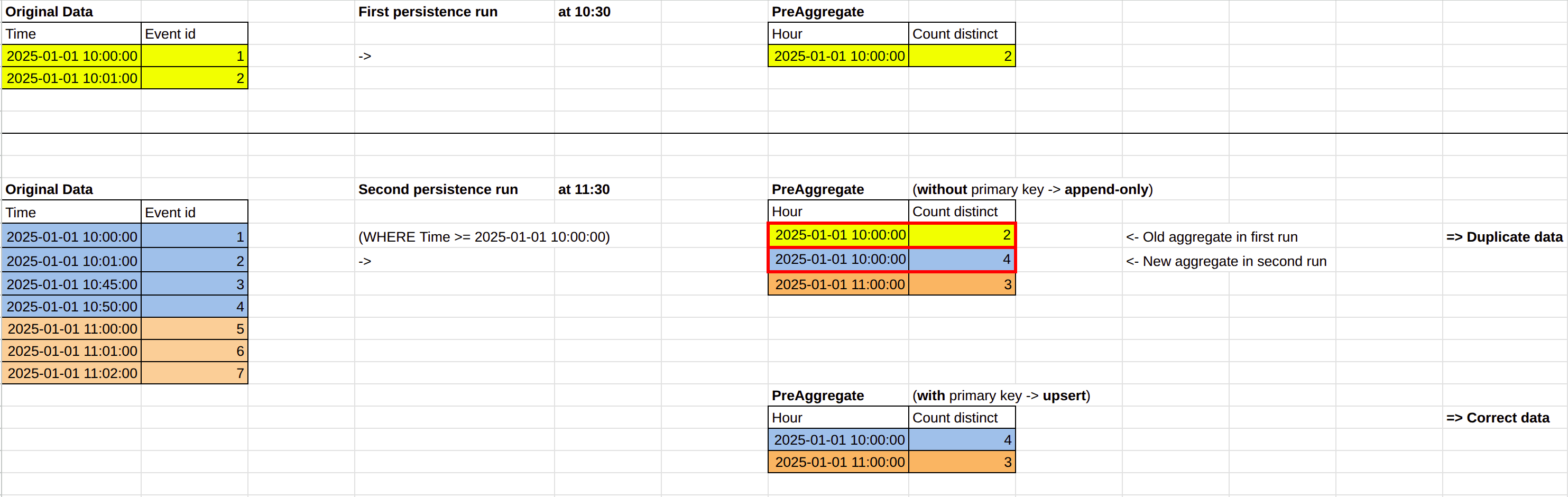
Note: The column names in incremental_column and primary_key refer to columns in the PreAggregate, not the source models.
For full syntax details, see AML Persistence.
Setting up built-in persistence
Step 1: Add persistence config
Add a persistence block to your pre-aggregate definition:
Dataset ecommerce {
models: [transactions]
pre_aggregates: {
agg_transactions: PreAggregate {
dimension created_at_day {
for: r(transactions.created_at)
time_granularity: "day"
}
dimension status {
for: r(transactions.status)
}
dimension country {
for: r(transactions.country)
}
dimension city {
for: r(transactions.city)
}
measure count_transactions {
for: r(transactions.id)
aggregation_type: 'count'
}
persistence: FullPersistence {
schema: 'persisted'
}
}
}
}
- The schema (e.g.,
persisted) must exist in your data warehouse - Your Holistics connection needs write permissions to this schema
Step 2: Trigger table creation
In Holistics, navigate to your Dataset and find the Pre-aggregate section. Click Run on the relevant pre-aggregate.
Once created, the table is ready for Aggregate Awareness to use.
Refreshing pre-aggregated tables
Pre-aggregated tables need to stay in sync with your source data. You can refresh them in several ways:
Manual refresh: Click the Run button in the UI (shown in the video above).
Scheduled refresh: Add a PreAggregateSchedule to your schedules.aml file:
const schedules = [
// Refresh specific pre-aggregates daily at 8:15 PM
PreAggregateSchedule {
cron: '15 20 * * *'
object: ecommerce_dataset
pre_aggregates: ['agg_transactions']
}
// Or refresh all pre-aggregates in a dataset
PreAggregateSchedule {
cron: '0 2 * * *' // 2 AM daily
object: ecommerce_dataset
}
]
API refresh: Coming soon (integrate with your existing orchestration tools).
How Holistics identifies tables
Holistics generates a unique key for each pre-aggregate based on its semantics:
- Dimension definitions (SQL/AQL)
- Measure definitions (SQL/AQL)
- Relevant relationships in the dataset
- Data source connection
If you change any of these (e.g., modify a dimension's definition), the key changes and Holistics will no longer use the old persisted table. You'll need to run persistence again.
Cross-branch reuse: Pre-aggregates in different git branches can share the same persisted table if they have identical semantics.
Automatic cleanup
Unused tables are automatically deleted after 7 days. To adjust this:
- Go to Administration Settings
- Find Pre-Aggregate Persistence TTL
- Set your preferred retention period

The countdown resets when:
- The table data is updated
- Someone queries the table
Learn more
- AML Persistence syntax reference
- Query Model Persistence (similar concepts)
External persistence
If you already have pre-aggregated tables in your warehouse (from dbt, Airflow, etc.), point Holistics to them with ExternalPersistence:
Dataset ecommerce {
models: [transactions]
pre_aggregates: {
agg_transactions: PreAggregate {
dimension created_at_day {
for: r(transactions.created_at)
time_granularity: "day"
}
dimension status {
for: r(transactions.status)
}
dimension country {
for: r(transactions.country)
}
dimension city {
for: r(transactions.city)
}
measure count_transactions {
for: r(transactions.id)
aggregation_type: 'count'
}
persistence: ExternalPersistence {
table_name: 'your_schema.agg_transactions'
}
}
}
}
The dimension and measure names in your pre-aggregate config must exactly match the column names in your external table.