Aggregate Awareness
Introduction
Querying billions of rows is slow and expensive. Data teams often solve this by building pre-aggregated tables (smaller, summarized versions of raw data). But this creates a new problem: analysts must know which table to query for each question, and picking the wrong one means slow queries or incorrect results.
Aggregate Awareness solves this. You define your pre-aggregated tables once, and Holistics automatically picks the right table for each query. No manual table selection required.
The result:
- Faster queries (fewer rows scanned)
- Lower costs (less compute)
- Same accuracy (automatic table matching)
- Zero friction for analysts (they query one model, Holistics handles the rest)
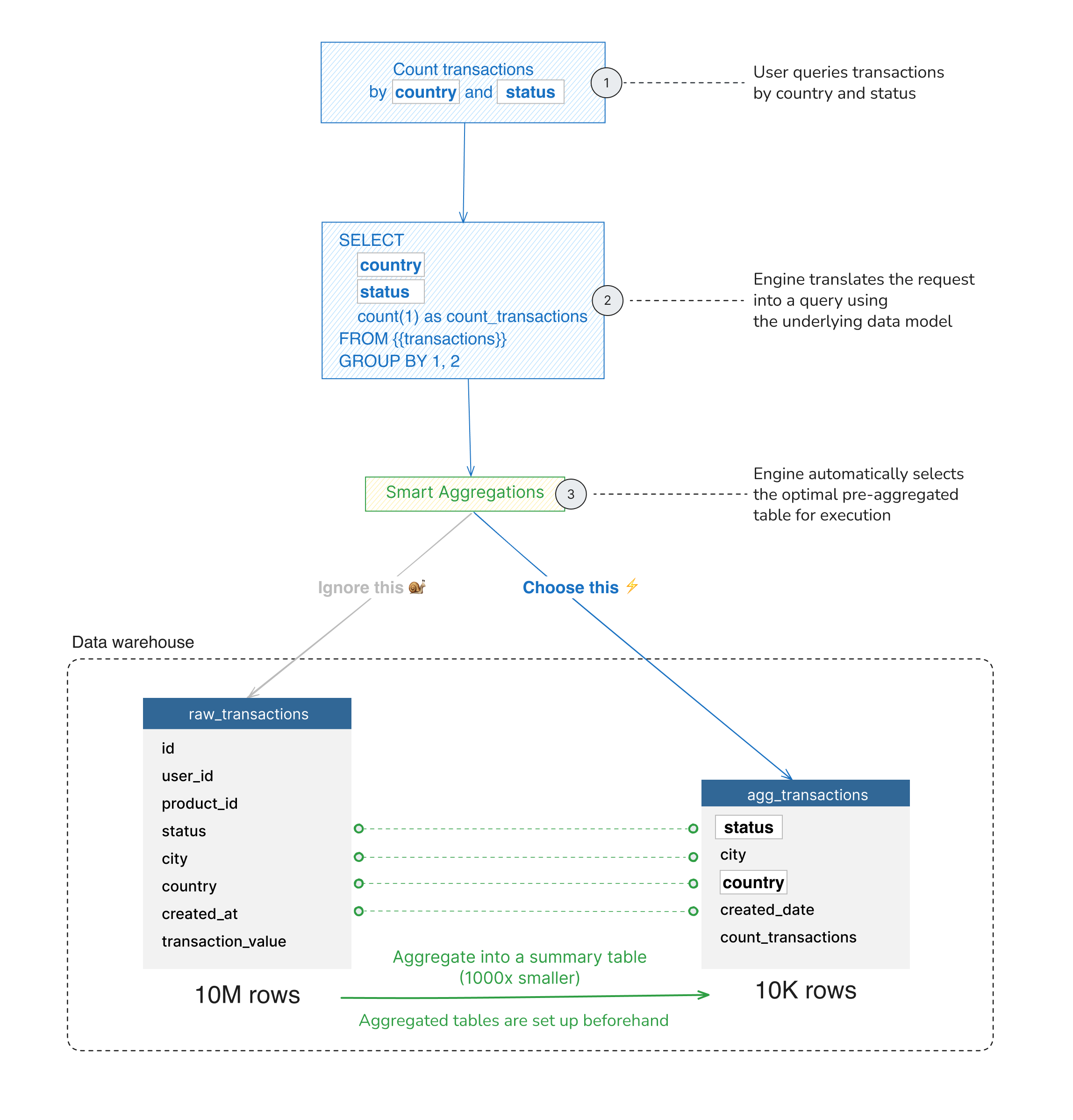
Key concepts
Before diving deeper, here are the core terms you'll encounter:
| Term | Definition |
|---|---|
| Pre-aggregate | Aggregation performed before query time, producing a condensed version of source data. |
| Pre-aggregated table | The output table from a pre-aggregate process (e.g., daily transaction counts instead of individual transactions). |
| Aggregate Awareness | The system's ability to automatically identify and use the right pre-aggregated table for each query. |
| Granularity | The level of detail in a dataset. Coarse = less detail (e.g., monthly totals). Fine = more detail (e.g., daily totals). |
Granularity examples:
monthhas coarser granularity thanday(country)has coarser granularity than(country, city)
How it works
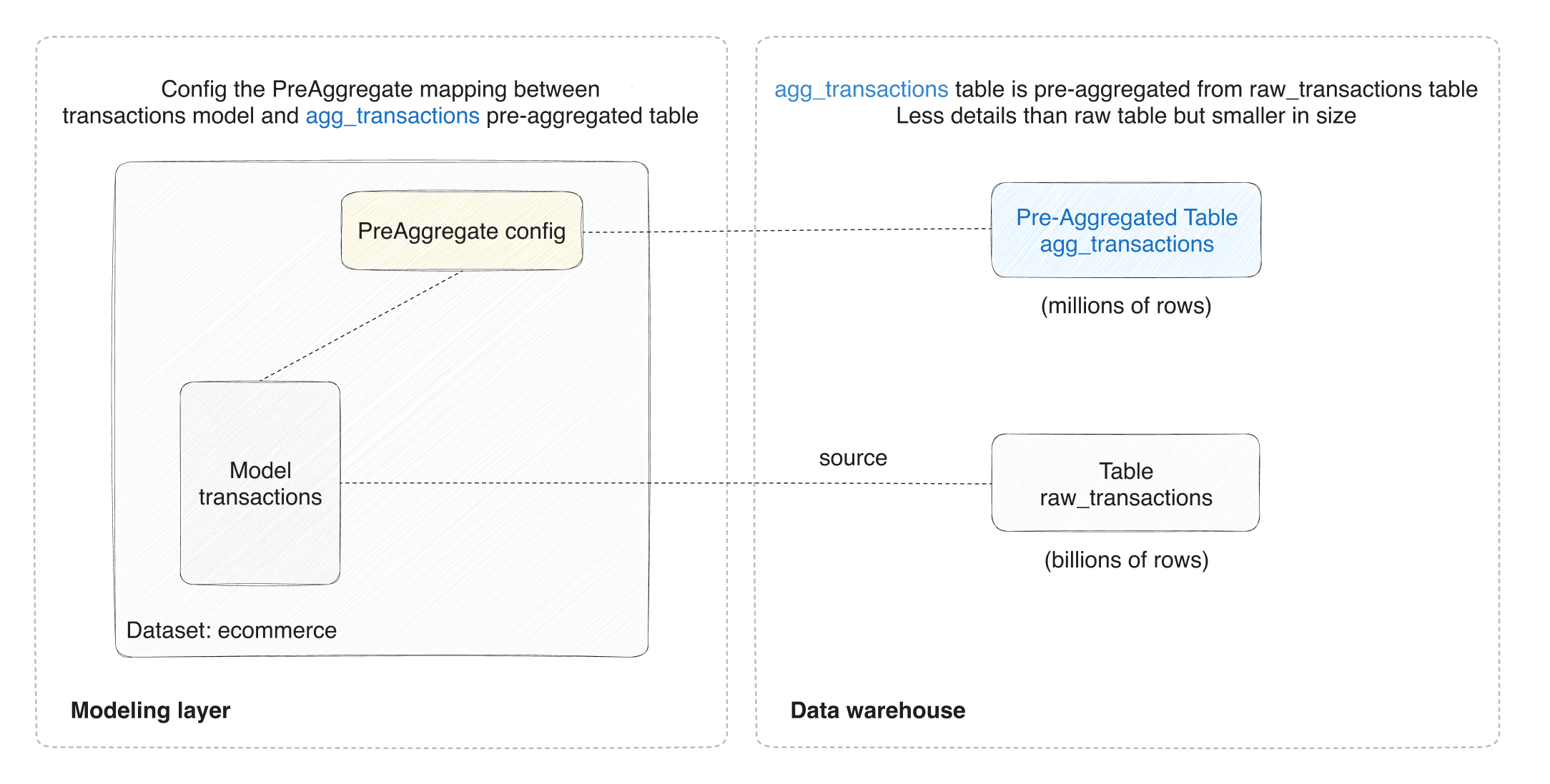
Setting up Aggregate Awareness takes two steps:
- Define the mapping between your raw model's fields and your pre-aggregated table's columns
- Connect the pre-aggregated table (use an existing table or let Holistics create one)
Once configured, Holistics inspects every query and automatically rewrites it to use the smallest table that can answer the question accurately.
The query rewriting process
When a user queries the transactions model:
- Holistics checks which dimensions and measures the query needs
- It finds pre-aggregated tables that contain those fields
- It selects the smallest qualifying table
- It rewrites the query to use that table instead of the raw table
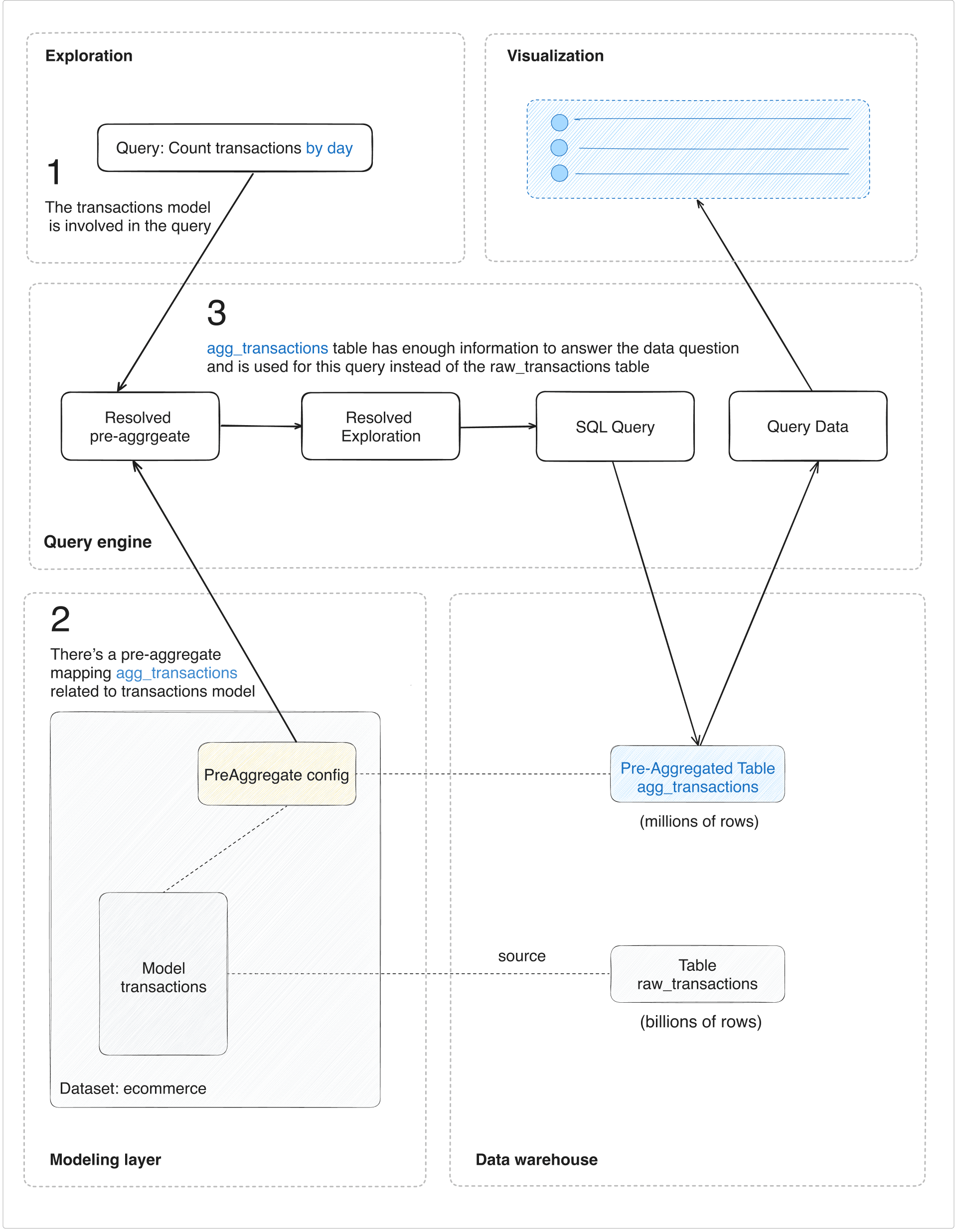
The key insight: Analysts work with one model (transactions). They don't need to know about pre-aggregated tables. Holistics handles the optimization transparently.
When to use Aggregate Awareness
Aggregate Awareness is most valuable when:
- Your raw tables have millions to billions of rows
- Users frequently query the same dimensions and measures (e.g., daily sales by region)
- Query performance or cost is a concern
Common use cases:
- Daily/weekly/monthly transaction summaries
- Regional sales rollups
- User activity aggregations
- Event counts by time period
Next steps
Ready to set it up? Follow the Quick Start Guide to configure your first pre-aggregate.
For the full AML syntax, see the PreAggregate reference.