Job queue system and workers
What is a worker/concurrent worker?
A worker (or concurrent worker) is an actor that actively processes jobs pushed into the queue. It sequentially handles jobs in the queue, with an available worker picking up the next job and processing it. Upon completion, the worker releases the job and proceeds to the next one.
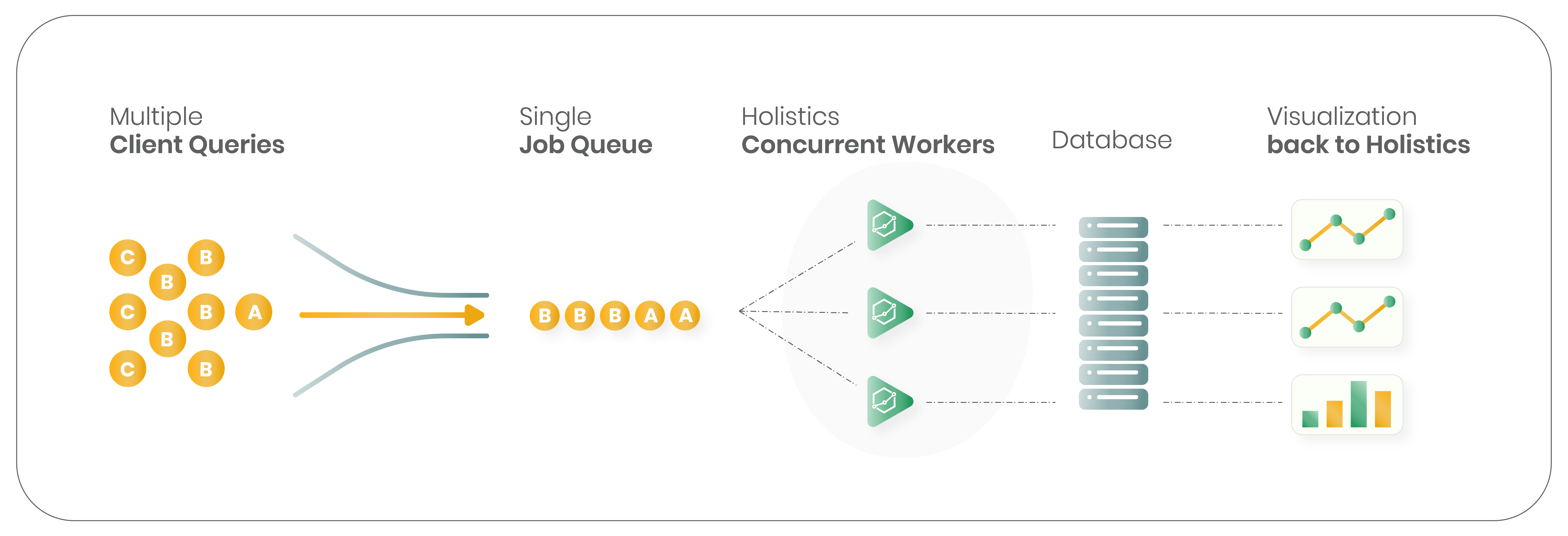
How does it work?
In Holistics, when a user opens a report, we construct an SQL query sent to the customer's data warehouse, wait for it to finish, and visualize the results.
Since the analytical SQL queries take time (seconds to minutes), it is usually not a good idea to handle this using synchronous web requests. A more scalable solution is to use a background job queue system.
A typical flow would look like:
- When a user views a report, a job is created and pushed into a job queue.
- A worker picks up the job, constructs the SQL queries, and then runs them against the customer’s data warehouse
- Once the query is finished, the result set is visualized and presented to the user’s browser.
What kind of actions will create a job?
Usually actions that involve running a SQL against the customer’s data warehouse:
- Users viewing dashboards
- Email schedules triggered
- Etc.
Why are concurrent workers important?
In an extreme scenario, with 20 users accessing 100 charts simultaneously, the Holistics application, without control, would generate 2000 database queries to the customers' database, potentially causing a crash, especially for a production database.
Holistics workers actively manage concurrent database queries by limiting the customer to 5 workers. This ensures that no more than 5 queries run simultaneously, with others queued up.
Therefore, increasing Concurrent Workers improves the querying process for both you and your customers. As your business scales, being charged based on Concurrent Workers is more cost-effective than the number of visualizations processed.
Job queues
Type of job queues
Each Holistics customer has their job queue and workers. This ensures one customer overloading the job queue will have zero to little effect on other customers’ systems.
Furthermore, depending on the nature of the job, it will be classified into different queues (or pools). For example, a Report job runs in a different queue than a Data Transform job.
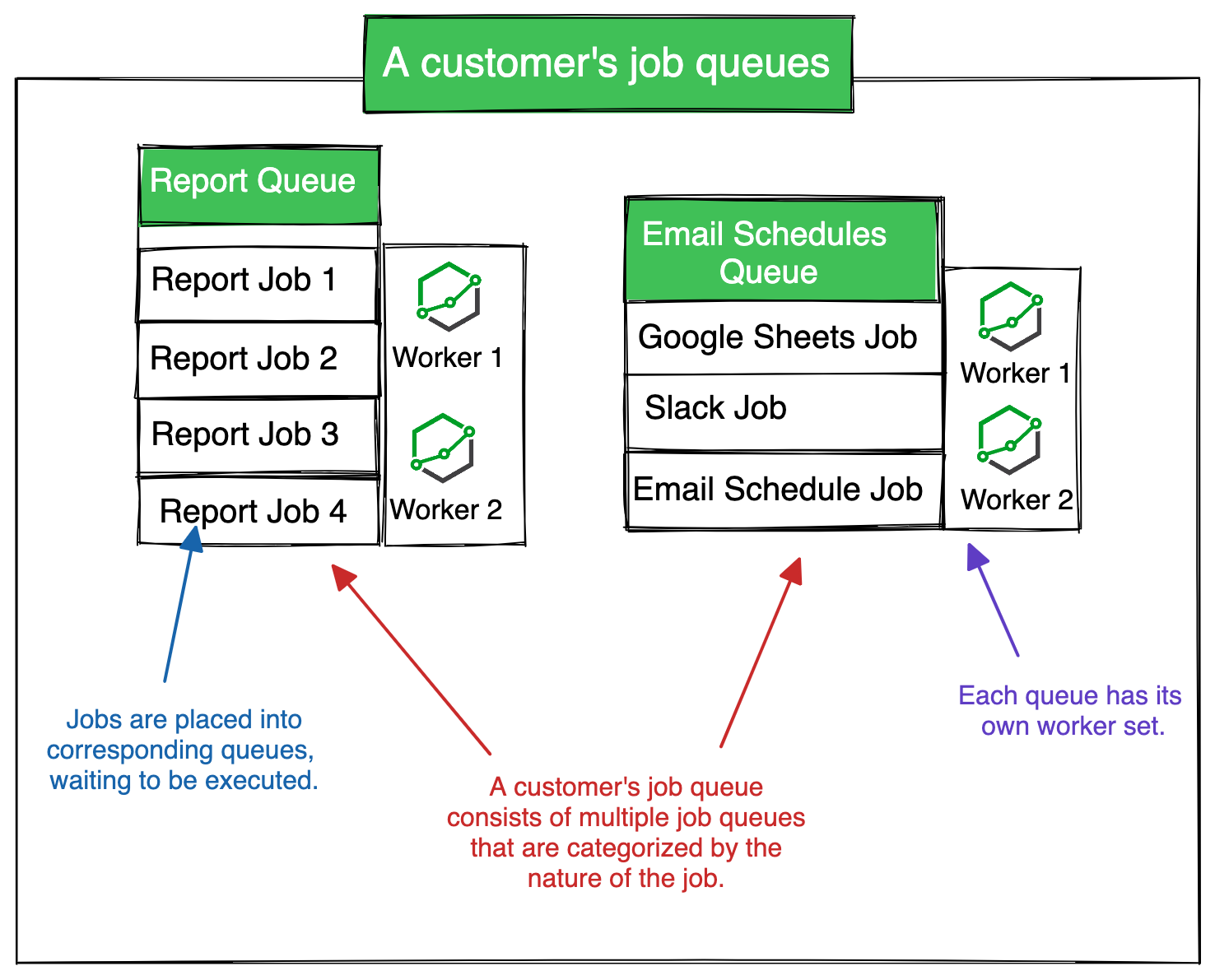
Default slots for specific job queues
Below is the default list of job queues and their default worker count. This is a soft limit, which means that it can be increased by purchasing more workers.
| Queue | Default Slot | Action included |
|---|---|---|
| Default | 20 | 1. Create/Update Custom Field 2. Refresh Models and Dependant Models |
| Adhoc Query | 5 |
|
| Filter | 3 |
|
| Report | 20 | Execute report/widget |
| Prefetch | 12 | 1. Prefetch Filter Cache 2. Preload Dashboard |
| Preview | 3 | 1. Validate Data Import 2. Preview Report/Query (Holistics Version < 3.0) |
| Export | 10 | 1. Export Dashboard 2. Export Dashboard Widget/Report |
| Email Schedule | 2 | Executing schedule (Email, Slack, SFTP, Google Sheet) |
| Data Source | 15 |
|
| Data Import (Version 3.0 and below) | 2 | Executing Data Import |
| Data Transform | 2 | Executing Data Transform (or Query Model Persistence) |
| Validate | 5 |
|
| Embed Analytics Queue | Default Slot | Action included |
|---|---|---|
| Embed | 0 |
|
If you want to enable our Embedded Analytics feature, please refer to our doc about Embedded Analytics for more information.
Your account’s configuration might be different from the default above. Please contact us by sending an email to [email protected] to find out your current setup.
Do note that the Embedded Analytics feature utilizes a special type of worker called Embed Worker. They are separate and can be manually adjusted from the Embed Analytics Manager.
To view the exact number of Job Workers in your workspace, go to Job Queues & Workers Monitoring
Life cycle of a job
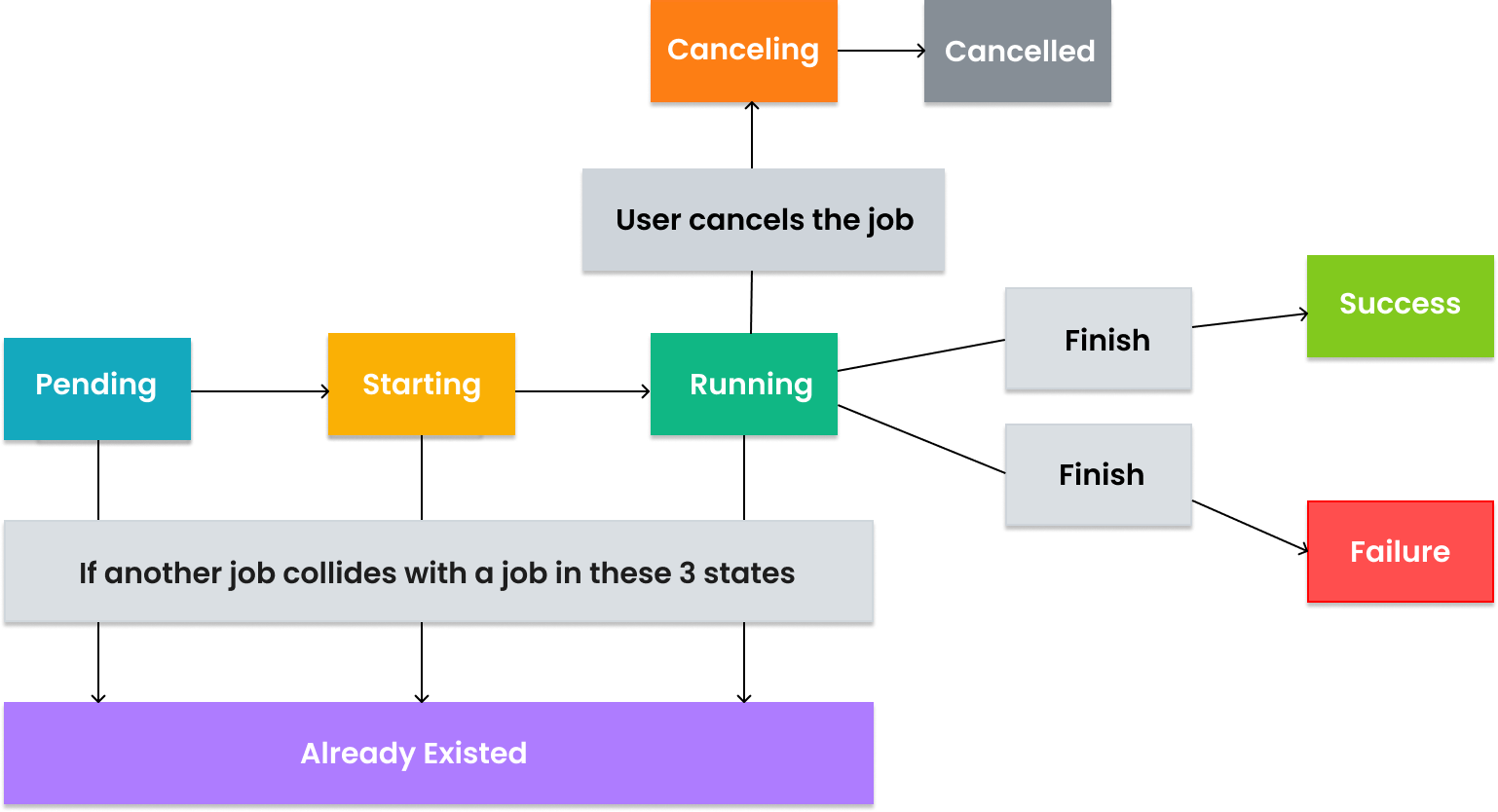
We have rolled out new Job Statuses to make them more intuitive.
Please refer to this Community post for more details.
Note that Holistics APIs still use the old Job statuses (created and queued).
| Status | Description | API value |
|---|---|---|
| Pending | This job is waiting for an available job worker in your workspace. | created |
| Starting | This job is done waiting (queuing) and being picked up (started) by an available job worker. It is going to be executed shortly. | queued |
| Running | This job is being executed by a job worker. | running |
| Success | If the job runs successfully, it will have success status. | success |
| Failure | If the job runs unsuccessfully, it will have failure status. | failure |
| Cancelling | While a job is running, if you manually cancel the job, it will have cancelling status. | canceling |
| Cancelled | If the job is cancelled successfully, it will have cancelled status. | cancelled |
| Existed | When a job have this status, it means that this job coincides with the another existing Pending/Starting/Running job. | already_existed |
Monitoring
To monitor your Holistics Jobs and Job Workers in real-time, please head to Job Monitoring.
FAQs
Can we reallocate some or all of the internal workers to be embedded workers?
Our core business model revolves around internal self-service analytics, with embedded analytics serving as a complementary add-on. We have not, from a commercial perspective, accommodated the transfer of workers or focused on supporting embedded dashboards.
You can purchase additional embedded workers for your embedded dashboards. By doing so, you'll ensure sufficient spare capacity, preventing customers from waiting for workers to be freed up when using the dashboard concurrently.
If your plan does not cater for embedded analytics, please fill out this form and our team will contact you regarding your options.